I’m involved with a project aiming to understand brown trout (Salmo trutta L.) movements in freshwater and estuarine environments.
Here, I want to share the methods we used to estimate the risks to brown trout when they migrate as sea trout smolts.
But first a little background.
Background
Brown trout are funny fish.
Some spend their entire lives in freshwater, e.g., a river, and are known as brown trout. Others migrate to marine waters, e.g., an estuary or sea, and are known as sea trout.
Sea trout return to freshwater a lot larger than brown trout, after feasting on the abundant food available in marine waters, and are able to produce more eggs. Brown trout might be smaller but they don’t run the risk of being eaten by any of the abundant marine predators.
Clearly, there is a fitness trade-off between getting big & producing more eggs (maximise your potential reproduction) and avoiding being eaten by any one of the abundant marine predators (maximise your potential survival to reproduction).
The decision to migrate is not, however, black and white. Finnock are brown trout that use estuaries and transitional waters for only short periods, e.g., a couple of months, presumably to feed.
So which strategy is best: brown trout, finnock or sea trout?
To study this question, we estimated the risk to sea trout of migrating through fresh, transitional and estuarine waters.
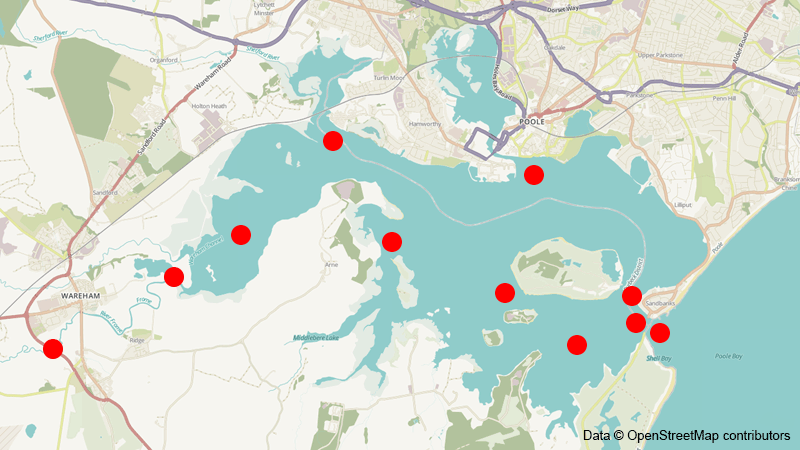
To estimate these risks, we acoustically tagged a sample of migrating sea trout smolts who’s migration pathways were recorded at listening receivers located in the different zones (Figure 1).
Location of listening receivers in Poole Harbour. Red dots represent approximate detection range of the receivers.
Analysis methods
Acoustic tracking data has the problem that detection is imperfect; we do not always detect a passing tag and so we don’t know if (i) the tag didn’t pass or (ii) whether it passed but was not detected.
This problem can and should be addressed statistically.
To estimate the risks to sea trout smolt of migrating through different zones, we used Bayesian State Space models (wikipedia: State-space representation).
I was reassured that others have used BSSMs in this context: Oliviez Gimenez’s paper explains clearly the theory of BSSMs for marked individuals and Chris Holbrook’s paper was an illustrative example of BSSM implementation for acoustically tagged lamprey.
In essence, BSSM estimates jointly the probability that a tag is detected at a particular location and the probability that it made the transition to that location successfully.
In our study, we assumed that all individuals shared the same detection and transition probabilities, i.e., that physical or behavioural differences between individuals were unimportant, and that individuals travelled independently.
We could therefore use the simple Cormack, Jolly & Seber (CJS) model given by:
where \(X_t\) is the total number of survivors from time \(t\), which includes \(u_t\) that is the number of newly marked individuals at time \(t\), \(Y_t\) is the total number of previously marked individuals encountered at time \(t\), \(p_t\) is the probability of detecting a tagged individual at time \(t\) (\(t = 2, ..., T\)) and \(\phi_t\) is the probability that a tagged individual transitions to time \(t + 1\) given that it is alive at time \(t\) (\(t = 1, ..., T − 1\)).
This formulation separates the nuisance parameters (the detection probabilities, \(p_t\)) from the parameters of interest (the transition probabilities, \(\phi_t\)) because the latter are found only in the second or “state” equation.
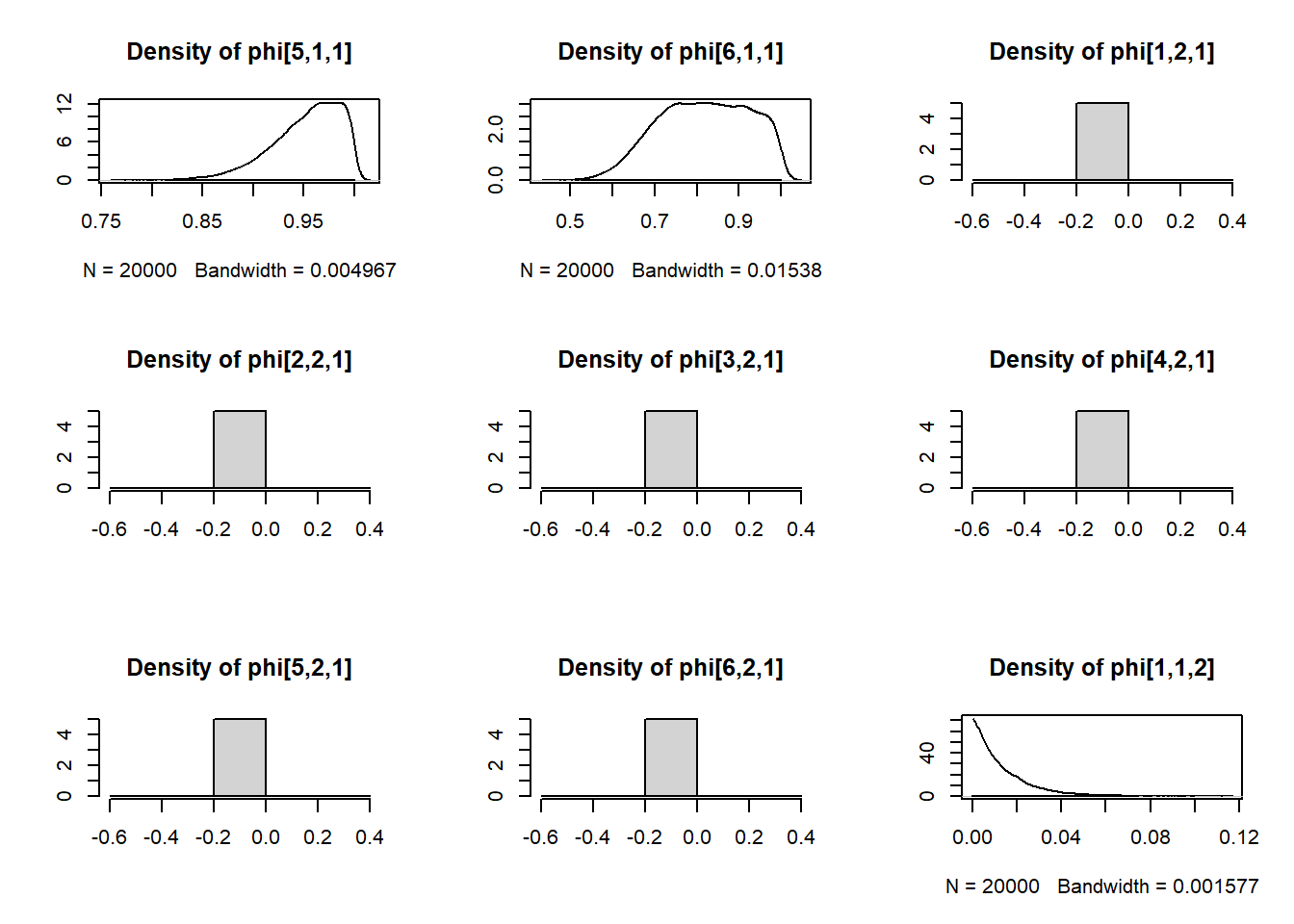
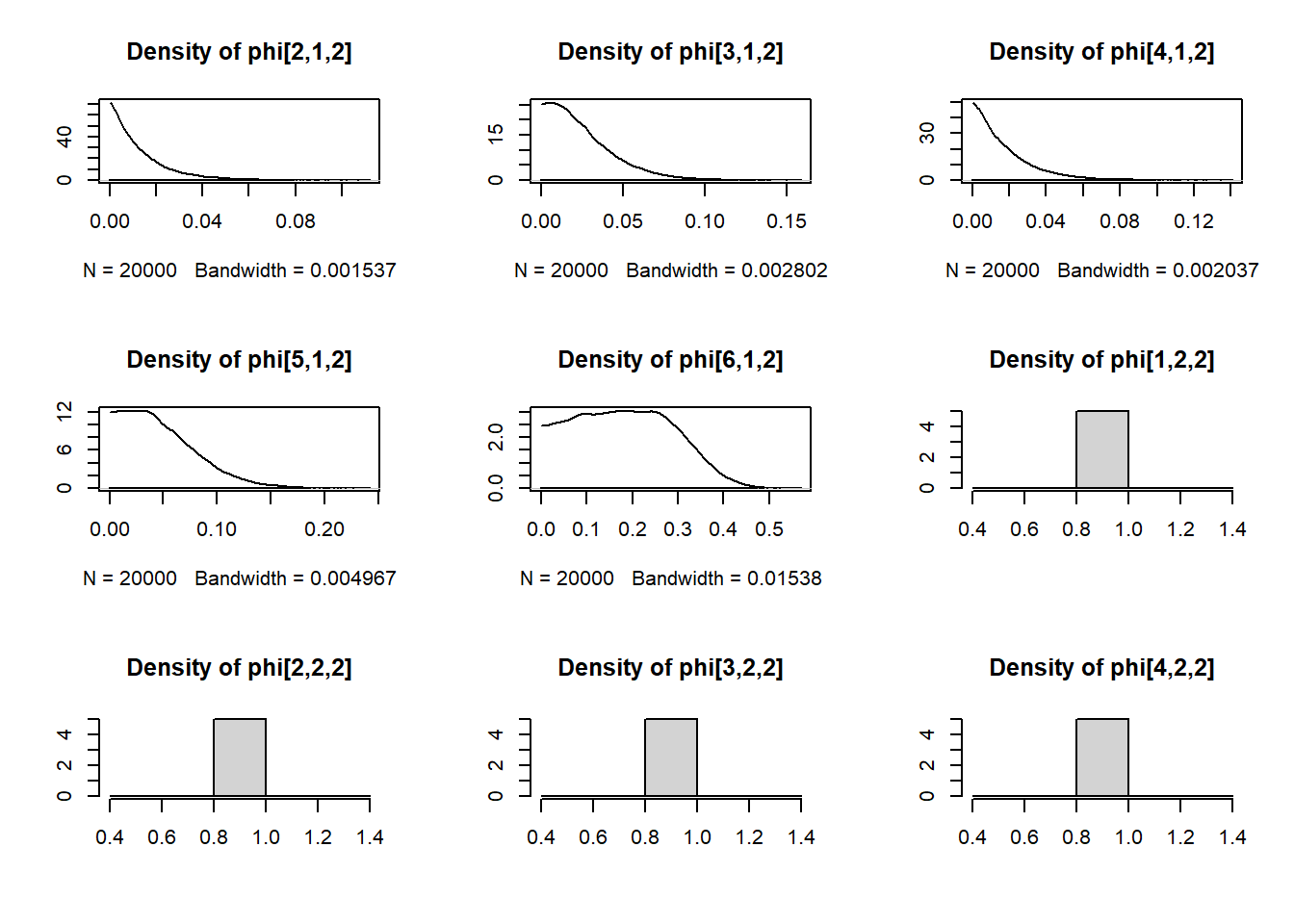
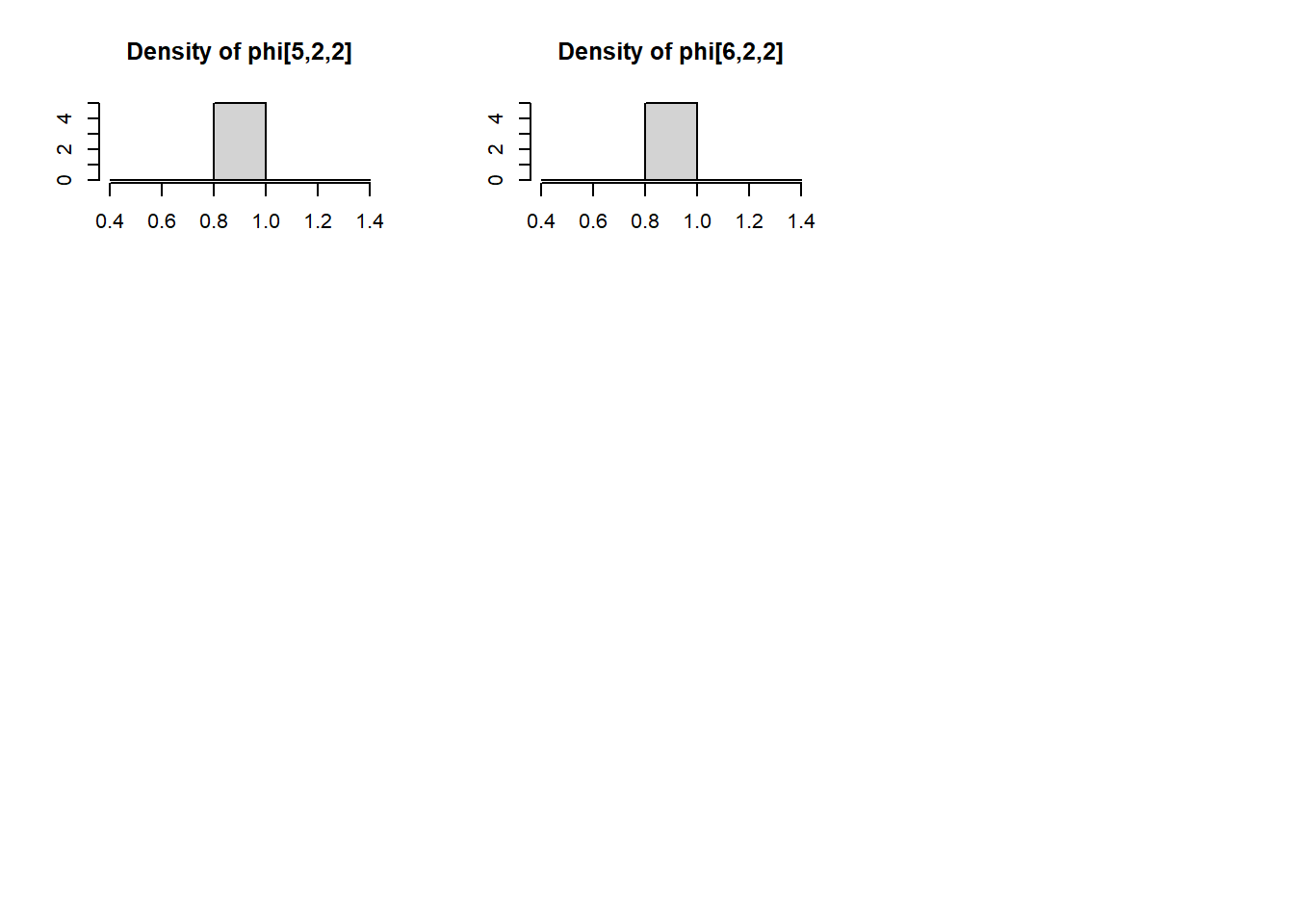
Using this model, we estimated values of \(p_t\) and \(\phi_t\) using the Monte Carlo Markov Chain (MCMC) method in JAGS. JAGS uses Gibbs sampling to explore the joint probability distribution of \(p_t\) and \(\phi_t\). Through an iterative process, weakly informative \(Beta(1, 1)\) prior distributions on \(p_t\) and \(\phi_t\) were updated with increasingly credible values until, after sufficient iterations, the best estimated values of \(p_t\) and \(\phi_t\) were taken to be the median of their posterior distributions.
We ran JAGS from within R using functions from package dclone. We ran three MCMC chains for 30,000 iterations, of which we discarded the first 10,000 as burnin.